```{r}
#| label: setup
#| warning: false
#| message: false
library("tidyverse")
library("lubridate")
library("janitor")
library("DT")
library("reactable")
library("gt")
```29 Report-making in R
So far, we’ve focused on the input to data analysis, but not as much on the output. We’ve stressed the need for “tidy” data, but I would be willing to bet that your instinct is to turn it into what we might call a report – something that is easier to read and consume rather than easy to analyze.
You’ve already seen that it’s almost impossible to read a table of numbers using R’s default method of printing them out. There are several useful packages available to make better-looking charts of numbers that will be more useful for both a finished document and for your own understanding.
29.1 What we want from tables and reports
- Numbers with formatting, such as percent, dollar signs and commas.
- Automatic wrapping of cells so that you don’t have to scroll to find columns.
- Totals and sub-totals shown on the same table as the detail.
- Printable tables that summarize your data succinctly so that you can write from it, or….
- Interactive tables with filtering, searching and sorting so you can explore it.
Libraries used
Be sure to install the following packages before attempting to follow this chapter.
reactable, for interactive tables that can incorporate small graphic elements.DT, for interactive tables with a few different features, including selectable columns.gtfor static tables with formatting, labelxling and totals. (It has a cousin,gtsummarythat we won’t be using that you might want to explore on your own.)
If you followed along int the first chapter setting up R and RStudio, you already have these.
Number formatting
There are a lot of ways to turn a big number into something readable in R. The problem is that most of these turn them into character, or text, columns. That’s ok if you don’t want to change the order in which the rows appear. But it wrecks the ability to sort (arrange) – “$4” is seen as larger than “$10” as text because 4 comes after 1 in the alphabet. The formatting options in the tables below are difficult to implement, but maintain sortability. The same thing happens with dates.
Most of these packages will be demonstrated with a random sample of the PPP data we’ve worked with so far.
Here is a sample of the data from PPP – we have to use it because it has the column types that give us problems: Dollar values and dates.
ppp <- readRDS (
url (
"https://cronkitedata.s3.amazonaws.com/rdata/ppp_sample.RDS"
)
) ppp_sample <-
readRDS( url ("https://cronkitedata.s3.amazonaws.com/rdata/ppp_sample.RDS") )29.2 Interactive tables with reactable
`reactable() is a version of the Javascript library used in many websites that you visit. It’s been adapted to R in the package you loaded above. It’s highly customizable, but it can involve a lot of typing to get a good table. The documentation is excellent and there are great examples in the wild.
The table in this document were made with reactable() in 2022.
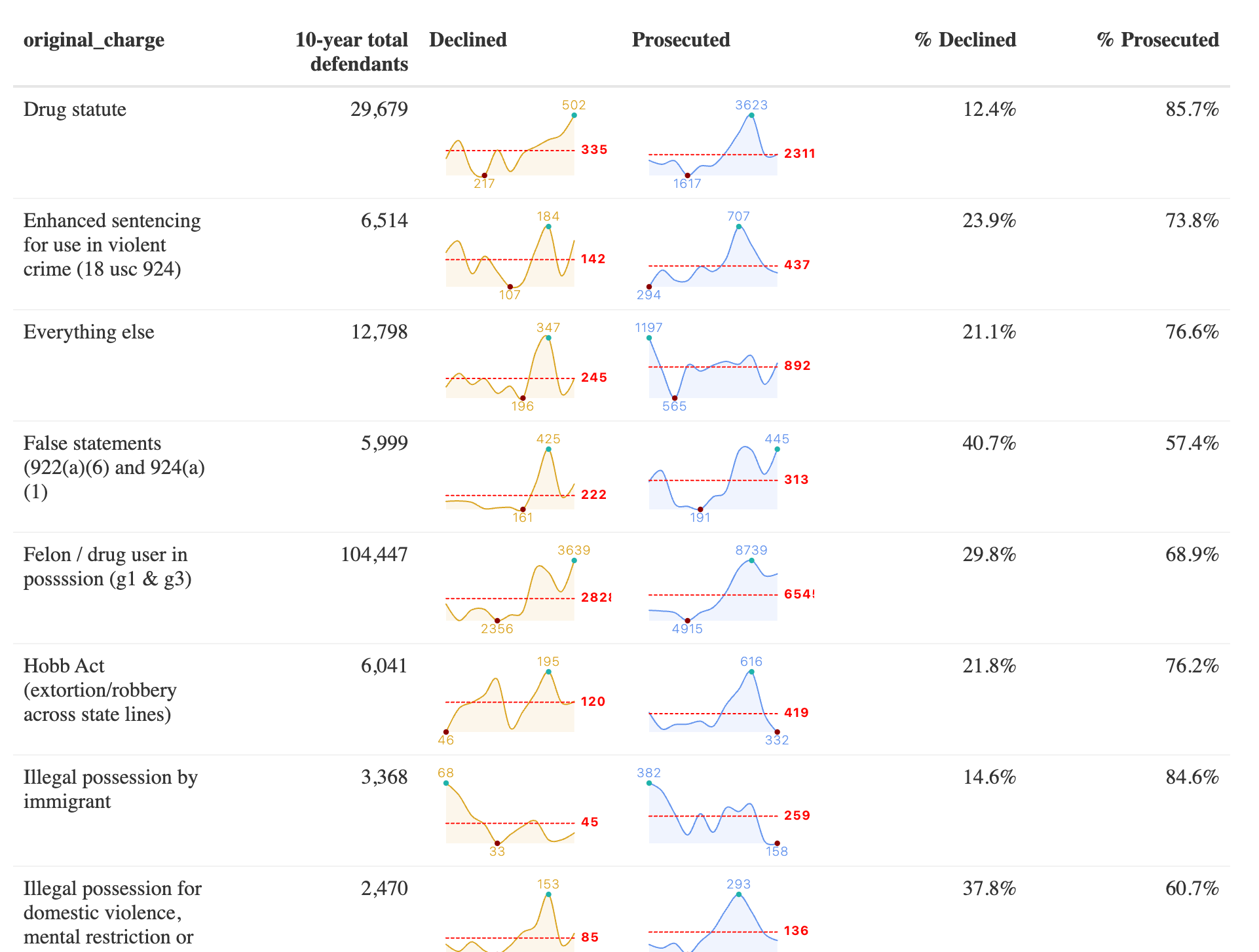
Let’s start by examining the data:
glimpse (ppp)Rows: 1,000
Columns: 12
$ date_approved <date> 2021-05-22, 2021-03-20, 2020-04-27, 2021-04-08, 20…
$ borrower_name <chr> "SANDRA GRAHAM", "SIBI LLC", "IDENTIFY YOUR SPACE L…
$ borrower_address <chr> "2901 W Mariposa St", "1630 W Guadalupe Rd 104", "4…
$ borrower_city <chr> "Phoenix", "Gilbert", "Chandler", "Tucson", "Page",…
$ borrower_state <chr> "AZ", "AZ", "AZ", "AZ", "AZ", "AZ", "AZ", "AZ", "AZ…
$ borrower_zip <chr> "85017", "85233", "85225", "85705", "86040", "85281…
$ loan_status <chr> "Paid in Full", "Paid in Full", "Paid in Full", "Pa…
$ loan_status_date <date> 2021-09-25, 2022-01-20, 2021-02-24, 2021-12-21, 20…
$ amount <dbl> 12395.00, 694100.00, 44722.00, 107500.00, 13181.00,…
$ forgiveness_amount <dbl> 12417.07, 698740.01, 45026.36, 108109.66, 13296.33,…
$ naics_code <chr> "611511", "518210", "541410", "711310", "561990", "…
$ forgiven <chr> "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Y…If you want to show all of the rows and all of the columns, you just have to add reactable() to the end of your code chunk:
ppp |>
reactable()That’s ok, but it’s not a lot better than the original – the numbers are still kind of inscrutible, and we can’t do much with it.
Add filters and sorts
Here’s a simple fix that will make every column sortable and searchable:
ppp |>
reactable( sortable=TRUE,
filterable = TRUE)But the numbers are still inscrutible. We want to see them as dollar values. (I’m adding the “compact” and “defaultPageSize” arguments to save a little room here:
ppp |>
reactable (
compact = TRUE,
sortable = TRUE,
filterable= TRUE,
defaultPageSize = 5,
striped = TRUE,
defaultColDef = colDef ( format= colFormat (currency="USD", separators = TRUE) )
)Notice that the dollar avmounts are shown as currency, but the still sort correctly! This is NOT true with most other solutions you see to this problem. The reason that the Zip code and the NAICS codes are NOT shown as dollars is because we defined them as text (or character) values – see it in the glimpse() above.
You might decide to stop here! It’s a much easier way to explore your data – and let your readers do the same – than to have to filter all the time. Just be aware that your browser and computer will only accept so many rows – don’t try it on something more than about 5,000 rows. And be sure to keep it paginated, or it will take forever to render.
Notably, you can create a date column in a form you like to see, and it will still sort properly.
Sometimes, you want to treat specific columns differently, or change the names. There are two approaches to this: 1) Use a select verb first to rename and choose your columns in the order you want to see them, or 2) set each column separately. Here, we’ll do a little of both:
ppp |>
select ( `Date` = date_approved,
`Name` = borrower_name,
`City` = borrower_city,
`Zip Code` = borrower_zip,
`Original Amount` = amount,
`Forgiven Amount` = forgiveness_amount,
`Was it forgiven?` = forgiven) |>
# now just copy from above
reactable (
compact = TRUE,
sortable = TRUE,
filterable= TRUE,
defaultPageSize = 15,
striped = TRUE,
defaultColDef = colDef ( format= colFormat (currency="USD", separators = TRUE) )
)That works! Now we want to format the date column in the way we like to see it – in American style.
ppp |>
select ( `Date` = date_approved,
`Name` = borrower_name,
`City` = borrower_city,
`Zip Code` = borrower_zip,
`Original Amount` = amount,
`Forgiven Amount` = forgiveness_amount,
`Was it forgiven?` = forgiven) |>
# now just copy from above
reactable (
compact = TRUE,
sortable = TRUE,
filterable= TRUE,
defaultPageSize = 15,
striped = TRUE,
defaultColDef = colDef ( format= colFormat (currency="USD", separators = TRUE) ),
columns =
list ( `Date` = colDef (format = colFormat(date = TRUE))
)
)There are ways to further customize the date, but this will work using the default date format for your country. Again, unlike other methods of doing this, the dates sort correctly.
29.3 Static tables with gt
For this example, we’ll use the Washington Post shootings data, which has something to count and create percentages for. This code reads the data, then creates a new column that breaks the original “armed” column into three possiblities – those who were armed with a gun (and nothing else), or “other or unknown”.
shootings <- readRDS(url("https://cronkitedata.s3.amazonaws.com/rdata/waposhootings.RDS")) |>
mutate ( is_armed = case_when ( armed == "gun" ~ "Gun",
armed == "unarmed" ~ "Unarmed",
.default = "Other or unknown")
)Take a look at it:
glimpse(shootings)Rows: 5,945
Columns: 6
$ name <chr> "Tim Elliot", "Lewis Lee Lembke", "John Paul Quintero", "Mat…
$ year <dbl> 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015, …
$ armed <chr> "gun", "gun", "unarmed", "toy weapon", "nail gun", "gun", "g…
$ ethnicity <chr> "Asian", "White, non-Hispanic", "Hispanic", "White, non-Hisp…
$ flee <chr> "Not fleeing", "Not fleeing", "Not fleeing", "Not fleeing", …
$ is_armed <chr> "Gun", "Gun", "Unarmed", "Other or unknown", "Other or unkno…Unlike reactable(), gt() is used when you have a very small table that you just want people to be able to read, with percentages and numbers properly formatted. Let’s try it using the number and percentage of armed victims. Let’s start with a simple table. (In this case, let’s not multiply the percentage by 100 – gt will do that later. )
shootings |>
count ( is_armed , name="Shootings") |>
mutate ( pct = Shootings / sum (Shootings)) |>
gt()| is_armed | Shootings | pct |
|---|---|---|
| Gun | 3406 | 0.57291842 |
| Other or unknown | 2136 | 0.35929352 |
| Unarmed | 403 | 0.06778806 |
shootings |>
count ( is_armed , name="Shootings") |>
mutate ( pct = Shootings / sum (Shootings)) |>
gt( ) |>
cols_label ( is_armed = "Armed?",
pct = "Percent")| Armed? | Shootings | Percent |
|---|---|---|
| Gun | 3406 | 0.57291842 |
| Other or unknown | 2136 | 0.35929352 |
| Unarmed | 403 | 0.06778806 |
Now we can format the “shootings” column:
shootings |>
count ( is_armed , name="Shootings") |>
mutate ( pct = Shootings / sum (Shootings)) |>
gt() |>
cols_label ( is_armed = "Armed?",
pct = "Percent") |>
fmt_number ( columns = c( Shootings),
decimals = 0) | Armed? | Shootings | Percent |
|---|---|---|
| Gun | 3,406 | 0.57291842 |
| Other or unknown | 2,136 | 0.35929352 |
| Unarmed | 403 | 0.06778806 |
That’s better!
let’s format the percentages:
shootings |>
count ( is_armed , name="Shootings") |>
mutate ( pct = Shootings / sum (Shootings)) |>
gt() |>
cols_label ( is_armed = "Armed?",
pct = "Percent") |>
fmt_number ( columns = c( Shootings),
decimals = 0) |>
fmt_percent ( columns = c(pct),
decimals = 1)| Armed? | Shootings | Percent |
|---|---|---|
| Gun | 3,406 | 57.3% |
| Other or unknown | 2,136 | 35.9% |
| Unarmed | 403 | 6.8% |
Much better. Now let’s add a total at the bottom:
shootings |>
count ( is_armed , name="Shootings") |>
mutate ( pct = Shootings / sum (Shootings)) |>
gt() |>
grand_summary_rows (
columns = c (Shootings, pct) ,
fns = list ( Total = "sum")
) |>
cols_label ( is_armed = "Armed?",
pct = "Percent") |>
fmt_number ( columns = c( Shootings),
decimals = 0) |>
fmt_percent ( columns = c(pct),
decimals = 1) | Armed? | Shootings | Percent | |
|---|---|---|---|
| Gun | 3,406 | 57.3% | |
| Other or unknown | 2,136 | 35.9% | |
| Unarmed | 403 | 6.8% | |
| sum | — | 5945 | 1 |
Formatting the summary rows has to be done separately, which is a pain. It’s only really useful when you want to send it to publication.
Pivoting and summarizing
The GT package is really useful when you want to present the results of one of your analyses that has percentages that you’ve pivoted. Here’s an example: Our question is:
Are Black victims more or less likely to have been armed than White victims?
- Compute the percentage of of “armed” answers within each ethnicity. This is a shortcut way to do that, with
nbeing the default name of thecount()answer.
shootings |>
filter ( ethnicity %in% c("White, non-Hispanic", "Black, non-Hispanic")) |>
count ( is_armed, ethnicity) |>
group_by ( ethnicity ) |>
mutate ( pct = n / sum (n)) - Pivot it to show the percentages within the two races:
shootings |>
filter ( ethnicity %in% c("White, non-Hispanic", "Black, non-Hispanic")) |>
count ( is_armed, ethnicity) |>
group_by ( ethnicity ) |>
mutate ( pct = n / sum (n)) |>
pivot_wider ( names_from = ethnicity,
values_from = pct,
id_cols = is_armed )Now create a formatted table:
shootings |>
filter ( ethnicity %in% c("White, non-Hispanic", "Black, non-Hispanic")) |>
count ( is_armed, ethnicity) |>
group_by ( ethnicity ) |>
mutate ( pct = n / sum (n)) |>
pivot_wider ( names_from = ethnicity,
values_from = pct,
id_cols = is_armed ) |>
gt ( ) |>
cols_label ( is_armed = "Armed?",
`Black, non-Hispanic` = "Black",
`White, non-Hispanic` = "White") |>
fmt_percent (
decimals = 0) | Armed? | Black | White |
|---|---|---|
| Gun | 60% | 59% |
| Other or unknown | 31% | 35% |
| Unarmed | 9% | 6% |