top100 |>
filter ( performer == "Taylor Swift") |>
arrange ( chart_date ) 12 A quick tour of verbs
We’ve described the Tidyverse as a set of packages linked together using common syntax and grammar. Much of its power comes from its basic verbs 1 . Mastering just a handful of them will equip you to do most of what a data journalist does, and will prepare you for more complicated endeavors.
This walkthrough gives you a little taste of what the key verbs do. More details are coming in subsequent chapters.
It depends on you continuing from the previous chapter. You can download a copy of the data that was saved into your project if you need it.
12.1 Starting a new Quarto document
Open or re-open the project you created in previous chapters. This starts you with a clean slate in the correct location.
Create a new Quarto document. Using the program you wrote in the last chapter, copy everything in through the setup chunk and delete anything else. Edit the YAML section to create a new title , and save it as
top100-02-analysis.qmd.Instead of importing from a text file, this time you’ll read in the R file you saved in the last lesson using the
readRDS()function.
top100 <- readRDS("hit100.RDS")
12.2 Filter and arrange
filter is the same idea as filtering in Excel, but it’s much more picky. In R, you have to match words exactly, including the upper- or lower-case.
arrange is R’s version of Excel’s sort.
Here’s how you would pick out all of Taylor Swift’s appearances on the Billboard top 100 list, in chronological order.
Caution
In R, a condition is tested in a filter by using two equal signs, not one.
So Taylor Swift has songs on the Billboard Hot 100 list more than 1,300 times since 2008.
Don’t count on filtering to count items!
Depending on your output formats, there are hard-coded limits to the number of rows that R will show you. With “paged” output like this, it will only show you the first 10,000 and won’t tell you how many more there are. We’ll come back to this.
Here’s how you’d list only her appearances at the top of the list – No. 1 is the lowest possible value for this_week, indicating the rank , then pick out just a few columns to list in order:
top100 |>
filter (performer=="Taylor Swift" & this_week == 1) |>
arrange ( chart_date) |>
select ( this_week, title, chart_date)Her first No. 1 hit was in 2012, and her most recent was in November 2023
12.3 Summary statistics in R
Listing each item that meets a condition might show you how many match your criteria, but it doesn’t help you aggregate your data. For that, you need the summarize() verb, calling specific summary functions:
n()– the number of rows.sum()mean()median()min()andmax()
summarize() answers the questions, “How many?” and “How much?”, or “Smallest” and “Largest”.
This code chunk will show the summary for all 341,000 rows:
top100 |>
1 summarize ( number_of_entries = n() ,
first_entry = min(chart_date),
last_entry= max(chart_date)
)- 1
- Each row defines a made-up descriptive name for the new columns created from summary functions.
Single vs. double “=”
- Use a single equals sign when you are naming a new column
- Use a double equals sign to see if one thing is the same as another
- Don’t ever name the new column the same thing as an existing column.
12.4 Grouping with summary statistics (aggregating)
Your questions will often be around the idea of “the most” or “the biggest” something. The group_by() verb creates separate analyses, or piles, for each unique item in the column. You then create a summary for those groups. We’ll go into this in a lot more detail in future chapters.
top100 |>
1 group_by ( performer) |>
2 summarize ( times_on_list = n() ) |>
3 arrange (desc ( times_on_list )) |>
head (10)- 1
- Collapse the data into one row for each performer.
- 2
- And fill it with the number of times that performer was on the list
- 3
- Sort it with the most popular performer first.
Adding the song title to the group_by() creates a more detailed list of tracks, but still collapses the weeks:
top100 |>
group_by ( title, performer) |>
summarize ( times_on_list = n() ,
last_time_on_list = max(chart_date),
highest_position = min(this_week)
) |>
arrange ( desc ( times_on_list) ) |>
head(25) So some of the titles that were on the list the longest never made it to #1. (You’ll learn later on how to make tables that are more easily navigated.)
We’ll go over how to make better-looking, more readable results in a few weeks. It’s more complicated than it should be.
12.5 Make a chart!
One motivator in learning R is its very sophisticated graphics. We’ll come back to this later in the semester, but you can just copy and paste this code to see how it might work.
I’ve made a dataset for you that contains the 26 No.1 songs that stayed on the Hot 100 for at least 52 weeks in this century. (Songs released for the first time 2023 aren’t eligible for the list)
# read the data
readRDS(
url ("https://cronkitedata.s3.amazonaws.com/rdata/top_songs.RDS")
) |>
# start the plot
ggplot (
aes ( x=chart_date, y=hit, color=this_week )
) +
geom_point( size= .25) +
# make it look a little better
labs( color = "Hot 100 #") +
theme_minimal( ) +
theme(axis.title.x = element_blank(),
axis.title.y = element_blank(),
legend.position= "bottom") 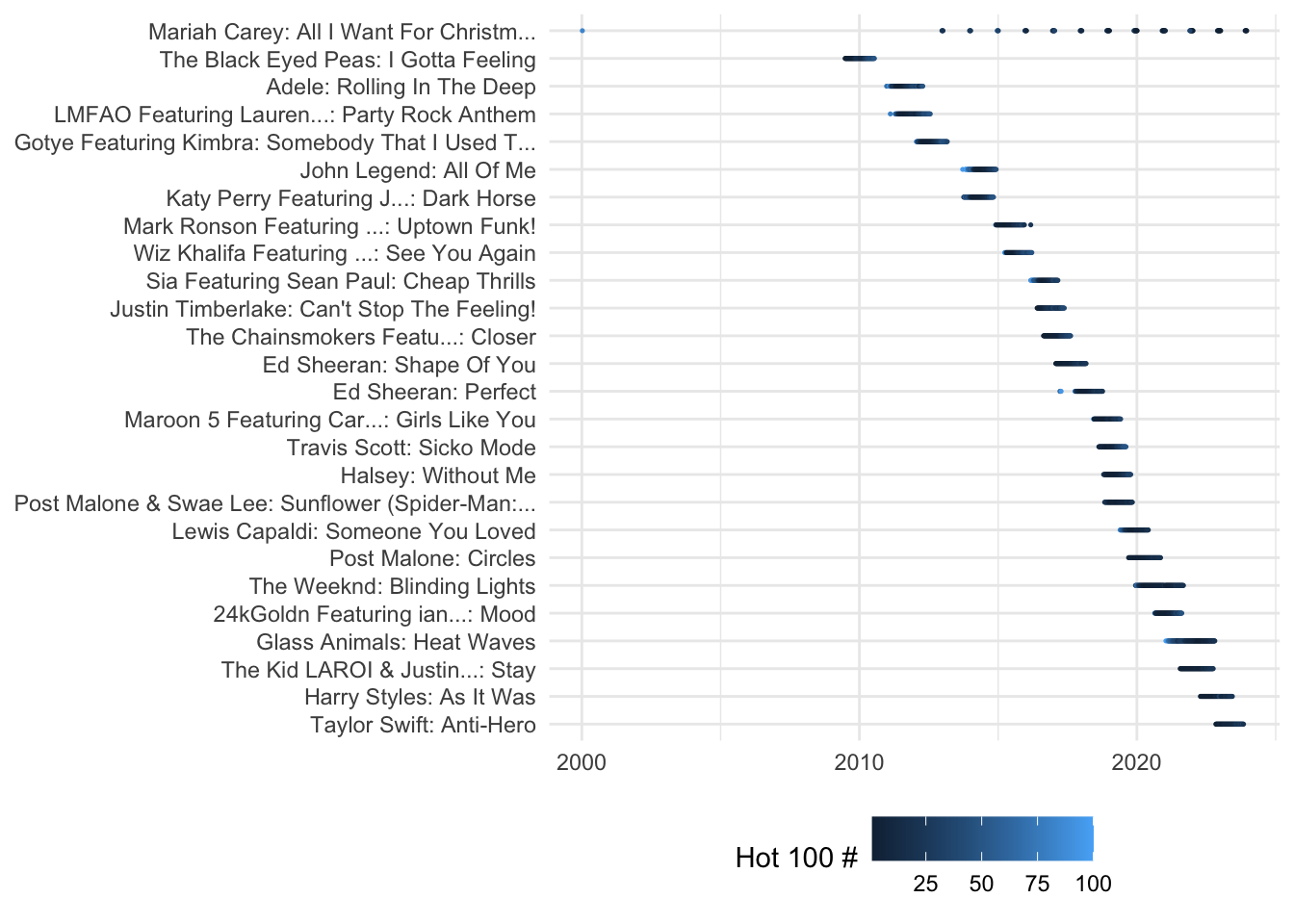
12.6 Thoughts on the verbs
You’ve now seen most of the key verbs of the tidyverse, and how they can be put together. They are:
mutate, which you saw in the last chapter, to create new columns.select, to pick out columns in the order you want to see themarrange, to sort a data framefilter, to pick out rows based on a conditionsummarizeto compute summary statistics like “how many?” and “how much? or”smallest” and “largest”group_byto create a single row for each unique item in a list.
Don’t worry if you don’t understand how this works or how to do it yourself. This walkthrough is just intended to show you how much you can do with just a few lines of code.
Technically, these are in a library called
dplyr, but it’s always included with the tidyverse↩︎