25 Open refine walkthrough
OpenRefine is a program designed to help you clean and standardize data. OpenRefine can be a little hard on your computer – it doesn’t handle large datasets very well, and it seems to work much better in Chrome than in other browsers.
This walkthrough goes through some of the PPP data to a) clean up the city names, b) standardize the borrower names, and c) split the suite or other detailed address from the street addresses.
Right-click to download the data for this walkthrough and save it into your projects folder
25.1 Installing OpenRefine
Download the latest version from the OpenRefine website and follow the instructions there to install.
Mac users: Unidentified developer
For Mac users, when you try to open it, it may tell you that you can’t because it’s from an unidentified developer. Go to the Applications folder on your computer, and use the CTL button before you click on the OpenRefine diamond. Once you successfully open it once, the program is whitelisted on your computer and you shouldn’t have to do it again.
Windows users
Windows users should take the “Windows kit with embedded Java” rather than trying to install the right version of Java yourself. You may have to go through the Windows Defender settings to set up an exclusion that allows Windows to run it, or get your system administrator to allow you to use it. You should only have to set this up once.
Limitations
OpenRefine works entirely in memory, and will start choking pretty quickly once you reach the 100,000 to 200,000 row range. You might need to partition your data or pull out just the columns you want to work on in order to clean a large dataset.
Following the walkthrough
Steps that you should take are shown in bullet points. The rest is explanation.
25.2 Starting OpenRefine
OpenRefine is a Java-based program that runs inside your browser, but lives on your computer instead of the internet. It runs much better in Chrome than in Safari.
Find the OpenRefine app on your computer, and double-click. When you first start it up, it will open with your default browser.
If it’s not Chrome, open a Chrome window and type the local address into its address bar:
localhost:3333or127.0.0.1:3333
Once it’s open in your browser, you’ll see something that looks like this:
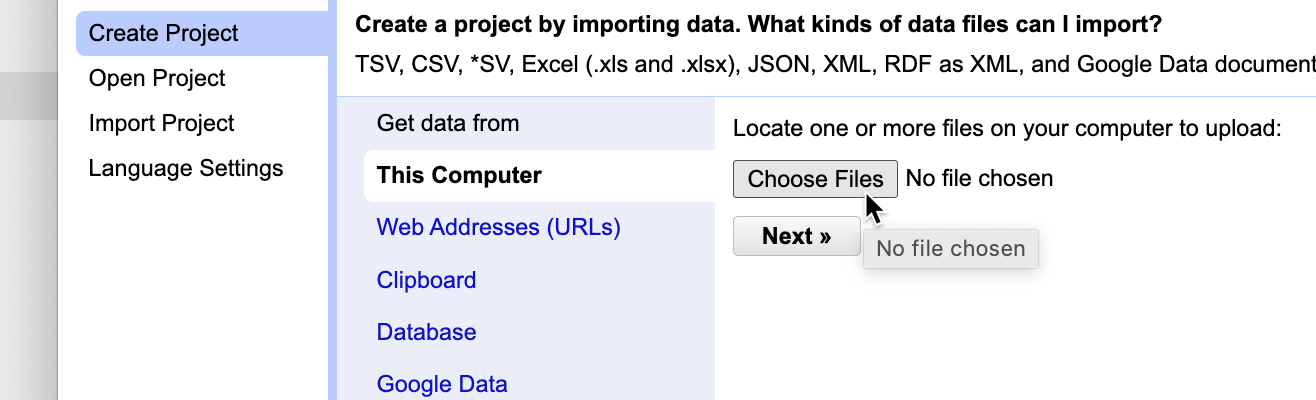
25.3 Importing data
OpenRefine works best on comma- or tab-delimited data. To create a dataset like that from R, use the function write_csv("path-to-csv-file.csv") , which can be used like any other verb after a continuation pipe.
To follow along with this tutorial, download the sample data file and save it into your R project folder .
In OpenRefine, look on the left of the screen and choose Create Project->Choose files, and navigate to the folder where you saved it. Choose the file you just saved, and consider changing the name of the project to something other than the file name. I called mine “ppp refined”.1
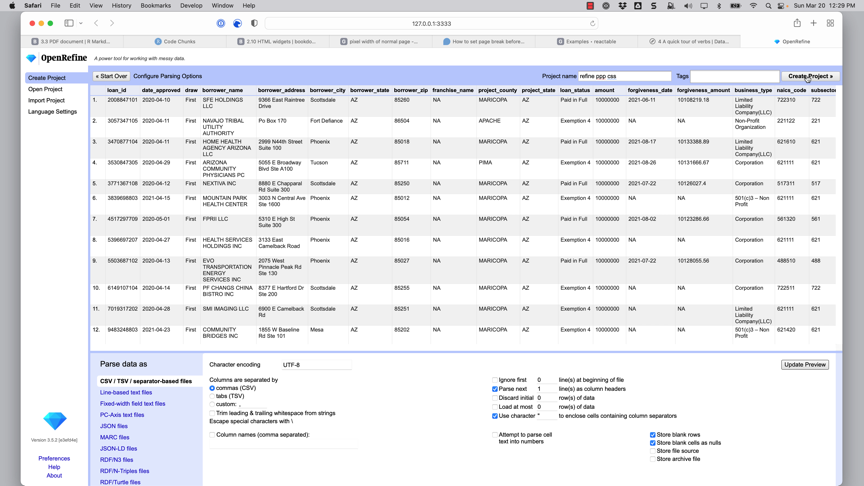
Usually, the default selections at the bottom work. They’re pretty self-explanatory, but if your data looks weird when it is imported, take a look for some options here.
I usually keep everything as “text” because OpenRefine doesn’t work as well with dates as numbers as it does with text. In this case, I’ve removed the amounts and dates from the data that we’re working with.
- Click the “Create Project” button to continue.
Returning to your project
You can also use that startup screen to re-open a project you’ve previously worked on. You don’t need to save it – OpenRefine saves it for you in the background. Use the Open tab to find your projects. If you need to move your project to another computer, you can use the Export options once it’s open.
Rename or copy columns
Eventually, you’ll want to re-import the results of your cleaning to your R or other programming environment, and it will cause you no end of trouble if you can’t match it up with the original data, or if columns have the same names.
Before you do any work on a column, be sure to either rename it or copy it into a new column. Someday you’ll thank me for this.
To rename something that is relatively simple to clean, such as the project_county in the PPP data, use the dropdown menu, and choose Edit column->Rename this column . I usually call it whatever the column name started as with a suffix _refined.
- Rename the columns
project_countyandproject_statenow.
To make a copy, use the dropdown menu Edit column->Add column based on this column and give it a name.
25.4 Facets
For many text columns, you can use facets to edit your data. Under your newly named project_state_refined, choose Facet->Text facet to get a menu on the left. It will then show you the values it found in that column, and the number of times each one appears, much like at group_by query.
OpenRefine only acts on rows that are selected, which makes using facets and filtering so powerful. You never have to worry that you’re changing something that you don’t see.
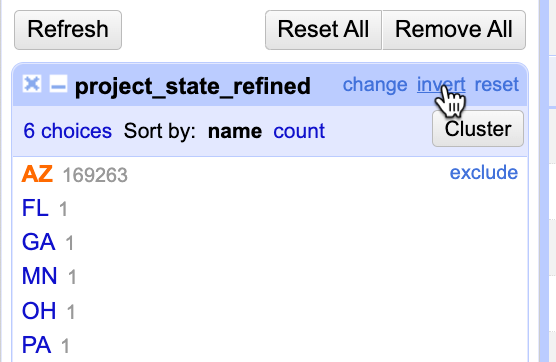
- To edit one by one, click on the state name you want to change, and choose the Edit option. You might combine all of the other states into an “OTHER” state.
A faster way to change everything that is selected at once is through the column’s menu.
Select “AZ” from the facet list, then choose invert from the top of the box to select everything except AZ.
Under the column dropdown, choose Facet->Edit Cells->Transform, and type “OTHER” (with the quotes) into the value box. (If you forget the quotes, you’ll see it come up with Null as an answer because it’s looking for a variable called
other, not the word “other”)With the same selection on, change the county name to “OUT OF STATE” using the same method.
25.5 Clustering
One reason a lot of reporters use OpenRefine is to take advantage of its fuzzy-matching to clean items like names and addresses. It provides about a dozen different algorithms that provide suggestions on ways to change unstandardized values in a column that often make a lot of sense.
This walkthrough will work on the city name.
Make a copy of the city and call it borrower_city_refined by using the dropdown Edit column->Add column based on this column . Otherwise you risk over-writing things incorrectly, and you’ll have to try to figure out where you went wrong.
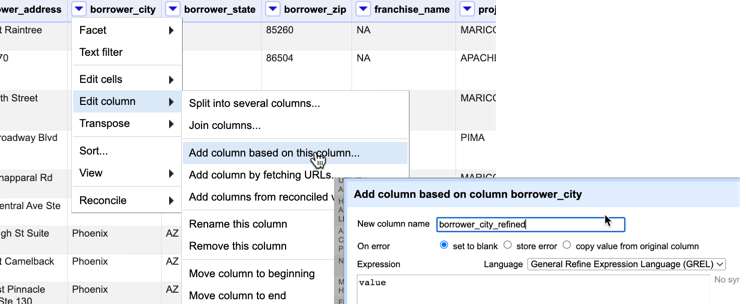
- Now create a facet on this new column.
You should see all of the bad values that were entered into that column by lenders and applicants. No one cared whether it was a valid city name.
Clustering details
You’ll often use many of the clustering approaches, then finish up with some other filters and facets when the clustering doesn’t work.
Some algorithms work better than others – some don’t catch natural clusters, and others find a lot of things to cluster that shouldn’t be combined. It’s unimportant for us what they actually do behind the scenes. Insetad, just know that they are different methods to find near-exact matches among character values.
One might look for all words that have the same letters but in any order, another might look for everything that matches the shortest phrase, and another might look for any 2 words in common. The order suggested by OpenRefine generally goes from the most strict to the most forgiving method, and from the easiest on your computer to the most resource-intensive. 2
On the facet, press the button that says “Cluster”. The first one chosen, called “key collision” by “fingerprint”, doesn’t come up with any suggestions.
Use the dropdown menu in the Keying Function box to choose the next option, “ngram-fingerprint”, and leave the option at 2.
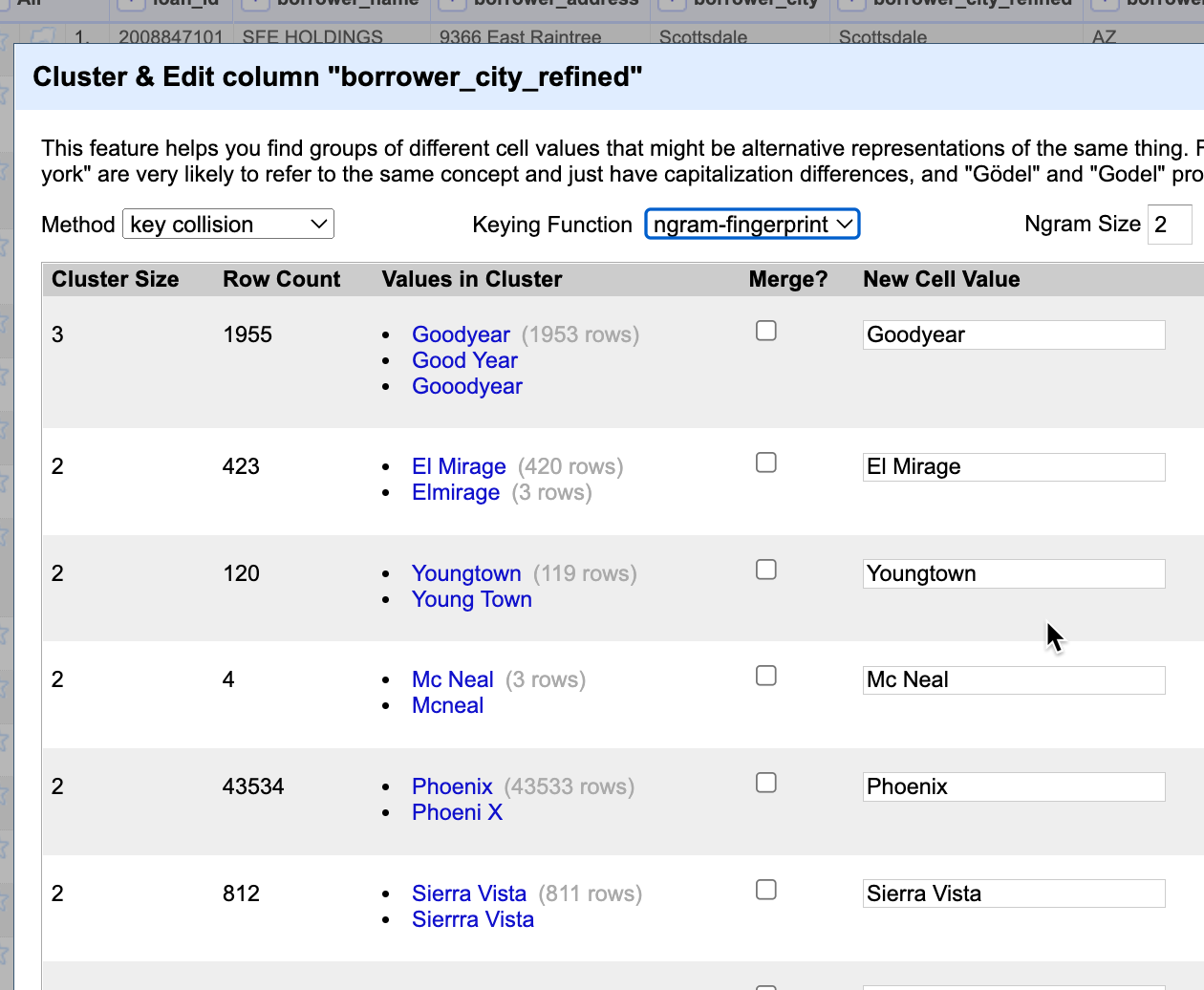
Now you can see how close some of the choices are.
Look through your choices, and select any that you want to combine. OpenRefine will change the least popular entry to the most popular, but you can change what you want it to be in the box provided. (At first, you’ll probably “Select all” and then just un-select the bad ones.)
Keep going with other clustering methods, turning off the ones you’re not sure should be combined and editing the value you want it to be. After exploring all of the options, I often end by going back to the ngram-fingerprint method and changing it to Ngram size of 1. That often catches the last remnants of one-word cities.
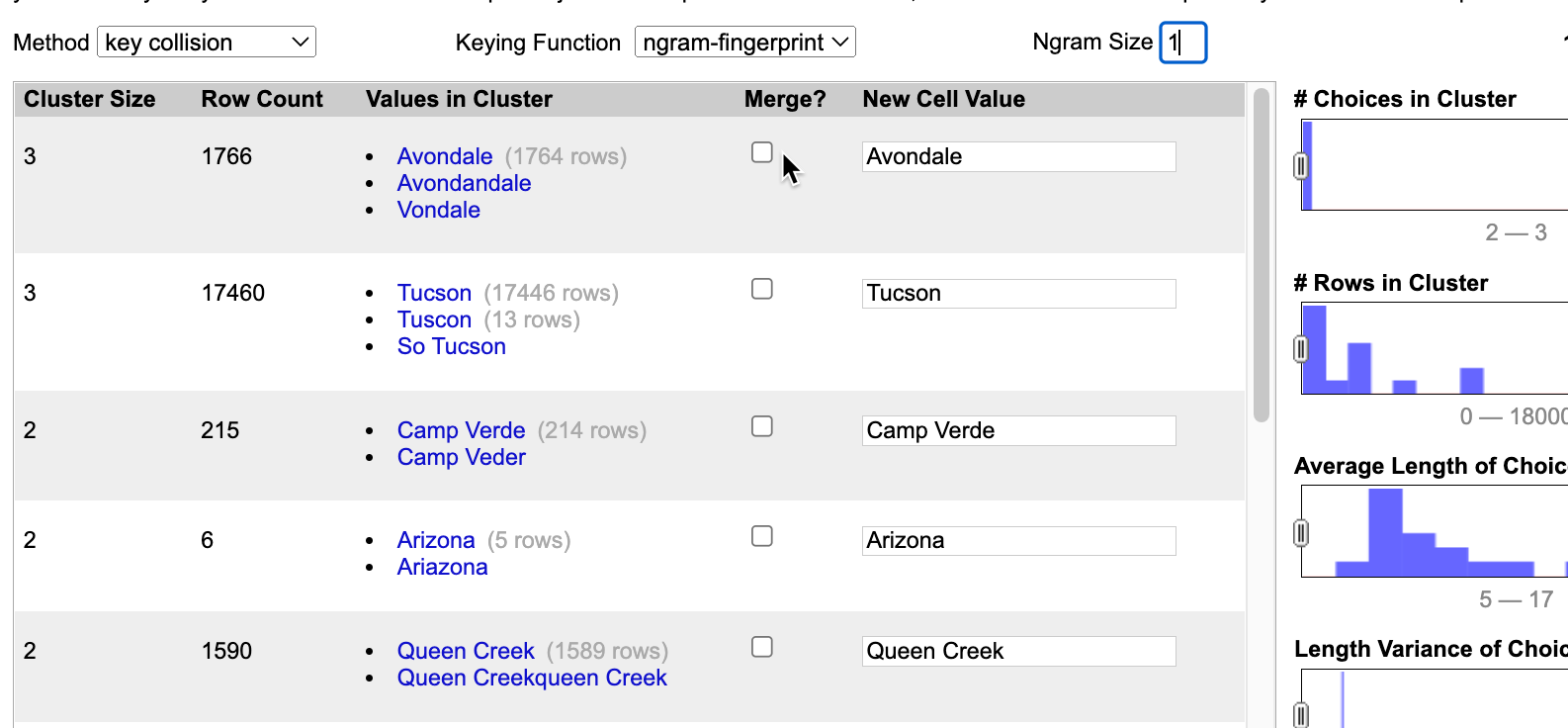
- Spend about 10-15 minutes cleaning up the cities, and see how close you can get to a good list.
Pro tip: Don’t try to do everything through clustering. You can’t really fine-tune the choices, so just stop when it’s getting close. You can then do the remaining things you care about manually. Try not to get too obsessed with getting it perfect. You’ll spend days on things that won’t matter, especially in early stages of your reporting when you don’t know what you care about.
Facet for long entries
In this list, though, there are addresses that are listed as cities. We may just want to remove those city names entirely, since we don’t really know what they are. There are several ways you might do this:
- Use the Facet->Customized facets->Text length facet menu item to create a facet by string length. Use the scrollbar to choose, say, more than 20 or 25 characters.
- Go through the list and select the ones that should not be changed, then
- Invert the selection and use the Transform menu to change the city to “Unknown”.
That got rid of most of them. You can go back to the original facet and select the ones at the top and change them as well.
The list isn’t perfect, but it’s much better than what we started with.
25.6 Filtering
Even after fixing all of the cities we can through clustering and faceting, there are usually some bad entries left over.
Simple filter
Instead of a Text Facet, choose Text filter from the dropdown menu. Generally, I use regular expressions in this box so I can control where in the column my target word or letters falls.
Try filtering for
^Phoeafter checking the “regular expression” box, and you’ll see a few stray entries for Phoenix that you can change in the facet window.
I tend to do this for anything I really care about getting right, such as larger cities or towns that I am going to report on. It’s often not worth the time to get a large list 100% accurate.
Complex filter
A complex filter will help you tag items for later use. One example is to tag items that contain apartment numbers, suite numbers or floor numbers after the address. Eventually, we may want to split the address column in two – one piece for the street address, and one piece for the detailed location.
Filtering for them first ensures that you won’t inadvertently split something that hasn’t met your condition in the first place.
Regular expressions work here the same way they did in str_detect in R, except that there is one backslash rather than two for special characters.
- Here is an example of how to find anything that has the word Suite or Ste after at least 10 other characters:
.{10,}\bS(ui)?te\b
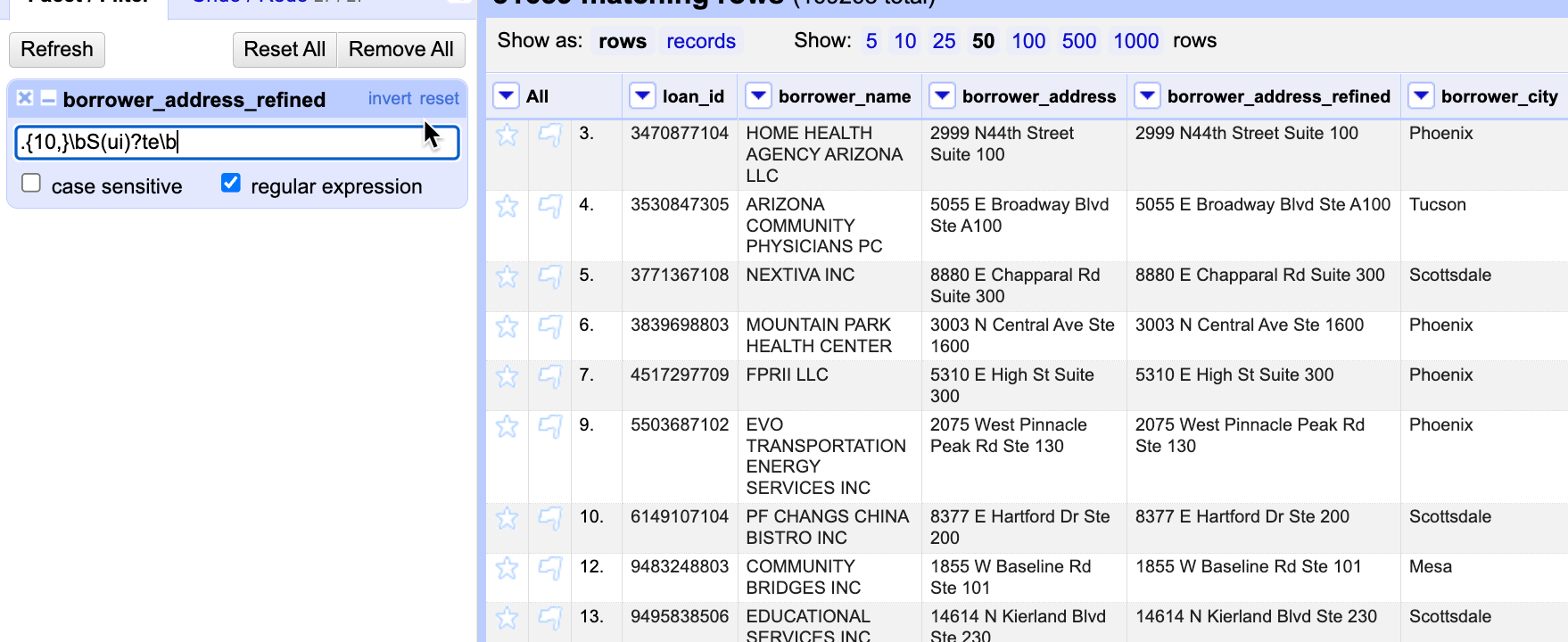
Using these filters, we can start splitting the values into their pieces.
Split by regex
- Choose Edit column->Split into several columns… from the dropdown menu, then use the regular expression as the “split” character. Make sure to un-check the “Guess cell type” and “Remove this column” boxes.
You can go back and look for entries that have “floor” or “apt” the same way, and split them in subsequent steps.
Split using OpenRefine programming language
That took care of the ones that had Suite numbers in them. Now we have to get the ones that have Apartment numbers in them. Use a regular expression to filter for the apartment numbers, and a Customized Facet->Facet by null to pick out the ones that haven’t already been split by our previous step.
OpenRefine has its own special language called GREL, which is really hard to use. But we’ll have to use it for this set because we’ve already split something else. This time, we have to put a value in the two columns based on pieces of a regular expression.
- With your filter on, choose
borrower_address_refined_2’s Transform menu. I’ll just show you how to do this, since it’s hard to explain:
-In the “Expression” box, copy and paste this code:
cells["borrower_address_refined"].value.match(/(.+)?\b(Apt .*)\b$/)[1]
This tells OpenRefine to extract two pieces from the original address column: The beginning (.+)?, the word “Apt” followed by anything at the end. The [1] tells OpenRefine to take the 2nd of those (its counting starts at zero, not one) and put it in the same column that we used for the Suite numbers. (NOTE: The GREL regular expressions are indicated by the two slashes at the beginning and end of the phrase (/). This is typical for regular expressions, and it distinguishes them from plain text.)
- Repeat the process, in the
borrower_address_refined_1column’s transformation, and use the index [0] at the end to get the cleaned street address.
25.7 Finishing up
- Try using the clustering and other transformation options to clean up the borrower names. Only change the ones you are sure should be combined.
Once you’re done, export the project to a new .csv file, and then import it into R. You can then select the cleaned up columns and the loan_id , then join it back to the original PPP data frame. Now you have a good set of cities, better ways to look at popular addresses, etc.
If you want to try another exercise, here is an old workshop I did for IRE in 2016.
Note: It lives in a different place than your folder on your computer. It’s actually a little hard to find, but you shouldn’t have to unless you’re moving between computers. You can always export all of the steps so that you can do them over on a new computer.↩︎
There is something called “reconciliation” in OpenRefine that tries to find matches in OpenCorporates lists of companies, or in a list that you provide. We’re not getting into that.↩︎