Attaching characteristics to a dataset
You’ll often want to learn more about a geographic area’s demographics, voting habits or other characteristics, and match it to other data. Sometimes it’s simple: Find the demographics of counties that switched from Trump to Biden as a way to isolate places you might want to visit. Another example from voting might be to find the precinct that has the highest percentage of Latino citizens in the county, then match that precinct against the voter registration rolls to get a list of people you might want to interview on election day. In these instances, the join is used as a filter, but it comes from a different table. .
This is also common when you have data by zip code or some other geography, and you want to find clusters of interesting potential stories, such as PPP loans in minority neighborhoods.
“Enterprise” joins
Investigative reporters often use joins in ways unintended by the data creators. In the 1990s, they dubbed these “enterprise” joins, referring to the enterprising reporters who thought of them. In these instances, reporters combine data sets in ways that find needles in haystacks, such as:
- School bus drivers who have had tickets for driving while intoxicated.
- Day care center operators who are listed on the sex offender registry.
- Donors to a governor who got contracts from the state
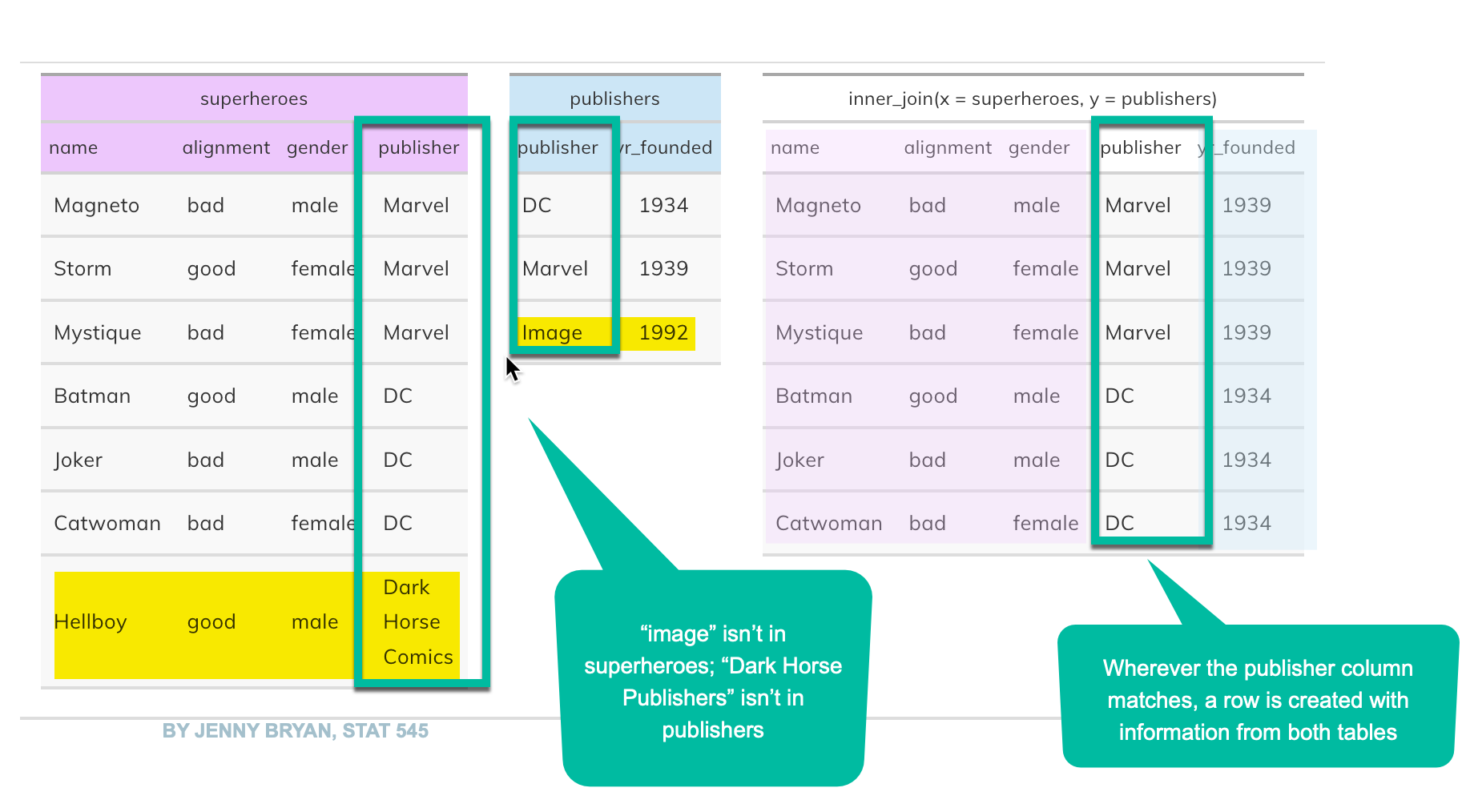
When you match these kinds of datasets, you will always have mistakes — some apparent matches are incorrect in the real world; some matches that should exist are ignored because of variations in names or other details. You always have to report out any suspected matches, so they are time consuming stories.
In the mid-2000s, when some politicians insisted that dead people were voting and proposed measures to restrict voting, almost every regional news organization sent reporters on futile hunts for the dead voters. They got lists of people on the voter rolls, then lists of people who had died through the Social Security Death Index or local death certificates. I never met anyone who found a single actual dead voter, but months of reporter-hours were spent tracking down each lead. Instead, they were people who had not yet been eliminated on the rolls but never voted. In others, they were people with the same names who had nothing to do with the dead person. In still others, they were the same people, but very much alive!
It’s very common for two people to have the same name in a city. In fact, it’s common to have two people at the same home with the same name – they’ve just left off “Jr.” and “Sr.” in the database. In this case, you’ll find matches that you shouldn’t. These are false positives, or Type I errors in statistics.
We rarely get dates of birth or Social Security Numbers in public records, so we have to join by name and sometimes location. If someone has moved, sometimes uses a nickname, or the government has recorded the spelling incorrectly, the join will fail – you’ll miss some of the possible matches. This is very common with company names, which can change with mergers and other changes in management, and can be listed in many different ways.
These are false negatives, or Type II errors in statistics.
In different contexts, you’ll want to minimize different kinds of errors. For example, if you are looking for something extremely rare, and you want to examine every possible case – like a child sex offender working in a day care center – you might choose to make a “loose” match and get lots of false positives, which you can check. If you want to limit your reporting only to the most promising leads, you’ll be willing to live with missing some cases in order to be more sure of the joins you find.
You’ll see stories of this kind write around the lack of precision – they’ll often say, “we verified x cases of….” rather than pretend that they know of them all.